
: a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a 3T-Token Budget")
MiniMax released MSA (MiniMax Sparse Attention), a sparse attention method built directly on Grouped Query Attention (GQA). It targets one bottleneck: the quadratic cost of softmax attention at long context. The MiniMax research team tested it inside a 109B-parameter Mixture-of-Experts model trained with native multimodal data. They also open-sourced an inference kernel and shipped a production model, MiniMax-M3.
What is MSA (MiniMax Sparse Attention)
MSA (MiniMax Sparse Attention) factors attention into two stages: an Index Branch and a Main Branch. The Index Branch decides which key-value blocks each query should read. The Main Branch then runs exact softmax attention over only those blocks.
Selection happens at block granularity, not per token. The default block size is Bk = 128 tokens. Each query and GQA group keeps k = 16 blocks. That fixes the per-query budget at kBk = 2,048 key-value tokens.
The two cost structures differ. Dense GQA attention scales per query as O(N), the full context. MSA scales as O(kBk), which stays fixed as N grows. The compute gap therefore widens as context length increases.
Selection is shared inside each GQA group but independent across groups. One key-value head serves several query heads, and they share one block set. Different groups can attend to different long-range regions.
How the Two Branches Work
The Index Branch adds only two projection matrices to a standard GQA layer. It defines one index query head per GQA group and one shared index key head. It scores visible key tokens, then max-pools those scores to the block level.
A Top-k operator then selects the highest-scoring blocks per query and group. The local block containing the query is always included. This prevents the selector from dropping the query’s immediate neighborhood.
The Main Branch gathers causally visible tokens from the selected blocks. It applies scaled dot-product softmax attention restricted to those tokens. Each query head keeps its own query projection but shares the group’s block set.
A visualization in the report shows what the learned indexer selects. Heads concentrate on the local diagonal and the first block. They reserve the rest of the budget for a few long-range stripes.
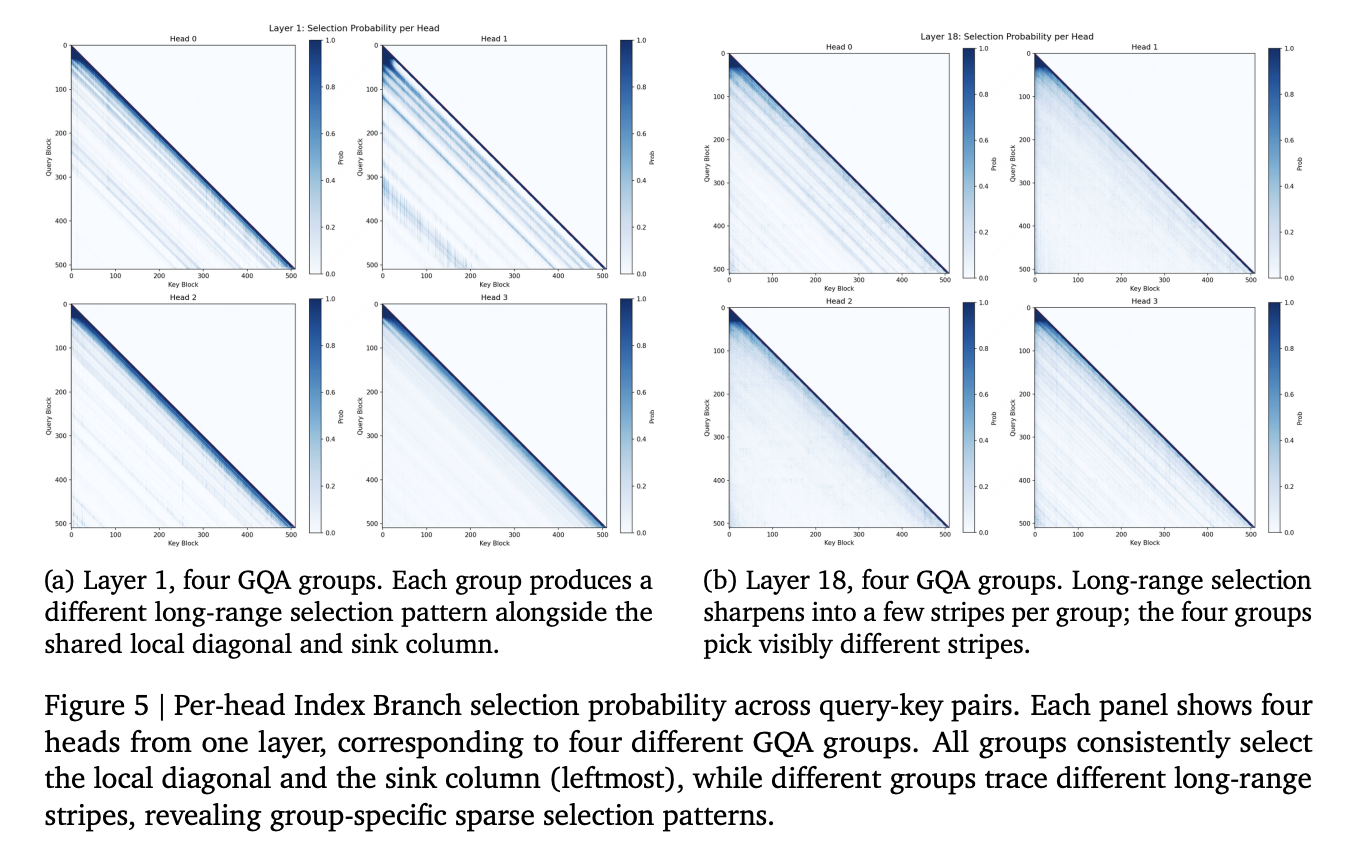
How MSA is Trained
Top-k selection is non-differentiable, so the language-modeling loss cannot train the index projections. MSA solves this with a KL alignment loss. The loss matches the Index Branch distribution to the Main Branch attention pattern. The teacher is the group-averaged Main Branch distribution over the selected tokens.
Three mechanisms stabilize sparse training. Gradient Detach applies stop-gradient to the Index Branch input. This confines the KL loss to the index projections, not the backbone. Without it, larger KL coefficients caused gradient spikes and loss divergence.
Indexer Warmup runs full attention in both branches for the first iterations. The indexer learns from the KL loss before it controls routing. The forced Local Block reserves one slot for nearby context.
Ablations shaped the final recipe. An early variant added an Index Branch value head with its own output. Once warmup is used, that value head is no longer necessary. The final design drops it on efficiency grounds.
MSA supports two training routes. MSA-PT trains from scratch after a 40B-token indexer warmup. MSA-CPT converts a dense GQA checkpoint trained on 2.6T tokens. It then continues for 400B tokens, including 40B tokens of warmup.
The Kernel Co-Design
Theoretical sparsity does not become speed without a matching GPU path. MSA pairs the algorithm with two kernel ideas.
The first is exp-free Top-k selection. Softmax preserves order, so ranking raw scores yields identical indices. The kernel skips the max, exp, and sum steps before selection. At 128K context with k = 16, it ran 5.1× faster than torch.topk. It also beat the TileLang radix-select kernel by 3.7×.
The second is KV-outer sparse attention with query gather. Iterating over KV blocks raises arithmetic intensity versus iterating over queries. The kernel packs ⌈128/G⌉ query positions into one 128×128 score MMA. A two-phase forward splits the attention and combine steps across CTAs.
The open-source kernel, fmha_sm100, targets NVIDIA SM100 GPUs. It ships dense FlashAttention plus sparse Top-k kernels under an MIT license. It supports BF16, FP8, NVFP4, and FP4 precision.
How MSA Compares To Other Sparse Methods
The research team positions MSA against four natively trained sparse designs.
The table below summarizes the differences it describes.
| Method | Backbone | Selection granularity | Indexer / selection signal |
|---|---|---|---|
| MSA | GQA | Block-level (B_k = 128), per-GQA-group Top-k |
KL alignment loss |
| NSA | MQA / MHA | Compressed + selected blocks + sliding window | Native (end-to-end) training |
| InfLLM-V2 | Dense↔sparse switchable | Parameter-free block selection + sliding window | Parameter-free (no trained indexer) |
| MoBA | GQA | Very large KV blocks (block-averaged keys) | LM gradient only |
| DSA | MLA (MQA mode) | Token-level; single Top-k shared across heads | ReLU lightning indexer |
MSA’s distinguishing pair is per-GQA-group Top-k sharing combined with block-level selection. This keeps KV reads contiguous while giving each group its own retrieval.
The quality side holds up. Both sparse models stay broadly competitive with the Full-Attention baseline.
The table below shows representative results under the 3T-token budget.
| Benchmark | Full | MSA-PT | MSA-CPT |
|---|---|---|---|
| MMLU | 67.0 | 67.2 | 66.8 |
| GSM8K | 76.2 | 77.7 | 73.7 |
| HumanEval | 61.0 | 64.0 | 57.9 |
| RULER-8K | 79.8 | 84.2 | 77.2 |
| RULER-32K | 75.0 | 77.5 | 75.7 |
| VideoMME | 41.11 | 45.48 | 39.65 |
After long-context extension, MSA-CPT stayed close to Full on HELMET-128K and RULER-128K. Each query still attends to only 2,048 key-value tokens.
Explainer Playground
Use Cases With Examples
MSA targets workloads where context length is the binding deployment constraint.
- Long-horizon agents: An agent that spans hundreds of reasoning and action steps accumulates a large transcript. Dense attention over that history grows quadratically. MSA holds the per-query budget at 2,048 tokens regardless of length.
- Repository-scale code reasoning: A coding agent loading a full repository can exceed hundreds of thousands of tokens. The indexer routes each query to the few relevant blocks. Irrelevant files stay outside the selected set.
- Persistent memory: A long-running assistant keeps growing conversational state. MSA reads a fixed-size slice of the most relevant blocks per query. The decoding cost stays roughly flat as memory grows.
- Long video understanding: The model is natively multimodal and trained on image and video data. MSA-PT scored highest of the three runs on several video benchmarks, including VideoMME and TemporalBench. Sparse selection scales to long visual token sequences.
Running the Kernel
The fastest path uses the Hugging Face kernels library.
# pip install -U kernels
from kernels import get_kernel
kernel_module = get_kernel("MiniMaxAI/msa", version=0)
sparse_atten_func = kernel_module.sparse_atten_func
sparse_atten_func(...)The repository also showcases the planner, indexer, and attention call directly.
import torch
from fmha_sm100 import fmha_sm100, fmha_sm100_plan, sparse_topk_select
page_size, topk = 128, 16
# Dense proxy pass: per-block max score from a cheap Q slice.
proxy_plan = fmha_sm100_plan(
qo_lens, kv_lens, proxy_q.shape[1],
num_kv_heads=1, page_size=page_size, output_maxscore=True,
)
_, max_score = fmha_sm100(
proxy_q, proxy_k_pages, proxy_v_pages, proxy_plan,
kv_indices=kv_indices, output_o=False, output_maxscore=True,
)
# Block scores -> selected KV block indexes.
kv_block_indexes = sparse_topk_select(
max_score.contiguous(), topk, num_valid_pages=num_pages,
)
# Sparse attention over the selected blocks.
sparse_plan = fmha_sm100_plan(
qo_lens, kv_lens, q.shape[1],
num_kv_heads=k_pages.shape[1], page_size=page_size, kv_block_num=topk,
)
out, _ = fmha_sm100(
q, k_pages, v_pages, sparse_plan,
kv_indices=kv_indices, kv_block_indexes=kv_block_indexes,
)These are the repository’s official usage examples. The inputs are paged key-value tensors that the caller prepares. The first run JIT-compiles the indexer, which can take a few minutes. Requirements are an SM100 GPU, CUDA Toolkit, and Python 3.10 or higher.
Strengths and Weaknesses
Strengths
- Per-token attention compute drops 28.4× at 1M context in the reported setting.
- Measured wall-clock speedups reach 14.2× prefill and 7.6× decoding at 1M on H800.
- The design adds only two projection matrices to a standard GQA layer.
- It supports both from-scratch training and conversion from dense checkpoints.
- The inference kernel is released under an MIT license.
Weaknesses and open questions
- The released kernel targets NVIDIA SM100; other architectures need separate work.
- A residual long-context retrieval gap remains versus full attention on some subtasks.
- Reported speedups assume a specific head configuration and the H800 setup.
- The KL loss adds training-time complexity over a plain dense layer.
- Results come from the MiniMax’s own evaluation suite, not third-party reproduction.
Check out the Full Paper and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us