

Apple is advancing AI and ML with fundamental research, much of which is shared through publications and engagement at conferences in order to accelerate progress in this important field and support the broader community. This week, the Fourteenth International Conference on Learning Representations (ICLR) will be held in Rio de Janeiro, Brazil, and Apple is proud to again participate in this important event for the research community and to support it with sponsorship.
At the main conference and associated workshops, Apple researchers will present new research across a variety of topics, including work unlocking large-scale training for Recurrent Neural Networks, a technique for improving State Space Models, a new approach to unifying image understanding and generation, a method for generating 3D scenes from a single photo, and a new approach to protein folding.
During exhibition hours, attendees will be able to experience demonstrations of Apple’s ML research in our booth #204, including local LLM inference on Apple silicon with MLX and Sharp Monocular View Synthesis in Less Than a Second. Apple is also sponsoring and participating in a number of affinity group-hosted events that support underrepresented groups in the ML community.
A comprehensive overview of Apple’s participation in and contributions to ICLR 2026 can be found here, and a selection of highlights follows below.
Recurrent Neural Networks (RNNs) are naturally suited to efficient inference, requiring far less memory and compute than attention-based architectures, but the sequential nature of their computation has historically made it impractical to scale up RNNs to billions of parameters. A new advancement from Apple researchers makes RNN training dramatically more efficient — enabling large-scale training for the first time and widening the set of architecture choices available to practitioners in designing LLMs, particularly for resource-constrained deployment.
In ParaRNN: Unlocking Parallel Training of Nonlinear RNNs for Large Language Models, a new paper accepted to ICLR 2026 as an Oral, Apple researchers share a new framework for parallelized RNN training that achieves a 665× speedup over the traditional sequential approach (see Figure 1). This efficiency gain enables the training of the first 7-billion-parameter classical RNNs that can achieve language modeling performance competitive with transformers (see Figure 2).
To accelerate research in efficient sequence modeling and enable researchers and practitioners to explore new nonlinear RNN models at scale, the ParaRNN codebase has been released as an open-source framework for automatic training-parallelization of nonlinear RNNs.
At ICLR, the paper’s first author will also deliver an Expo Talk about this research.
Speedup from Parallel RNN Training
Performance of Large-Scale Classic RNNs
State Space Models (SSMs) like Mamba have become the leading alternative to Transformers for sequence modeling tasks. Their primary advantage is efficiency in long-context and long-form generation, enabled by fixed-size memory and linear scaling of computational complexity. To Infinity and Beyond: Tool-Use Unlocks Length Generalization in State Space Models, a new Apple paper accepted as an Oral at ICLR, explores the capabilities and limitations of SSMs for long-form generation tasks. The paper shows that the efficiency of SSMs comes at a cost of inherent performance degradation. In fact, SSMs fail to solve long-form generation tasks when the complexity of the task increases beyond the capacity of the model, even if the model is allowed to generate chain-of-thought (CoT) of any length. This limitation arises from the bounded memory of the model, which limits the expressive power when generating long sequences.
The paper shows that this limitation can be mitigated by allowing SSMs interactive access to external tools. Given the right choice of tool access and problem-dependent training data, SSMs can learn to solve any tractable problem and generalize to arbitrary problem length and complexity (see Figure 3). The work demonstrates that tool-augmented SSMs achieve strong length generalization on a variety of arithmetic, reasoning, and coding tasks. These findings highlight SSMs as a potential efficient alternative to Transformers in interactive tool-based and agentic settings.
Unified multimodal LLMs that can both understand and generate images are appealing not only for architectural simplicity and efficiency, but also because shared representations can result in deeper understanding and better vision-language alignment, and can enable unique capabilities like image editing through instructions.
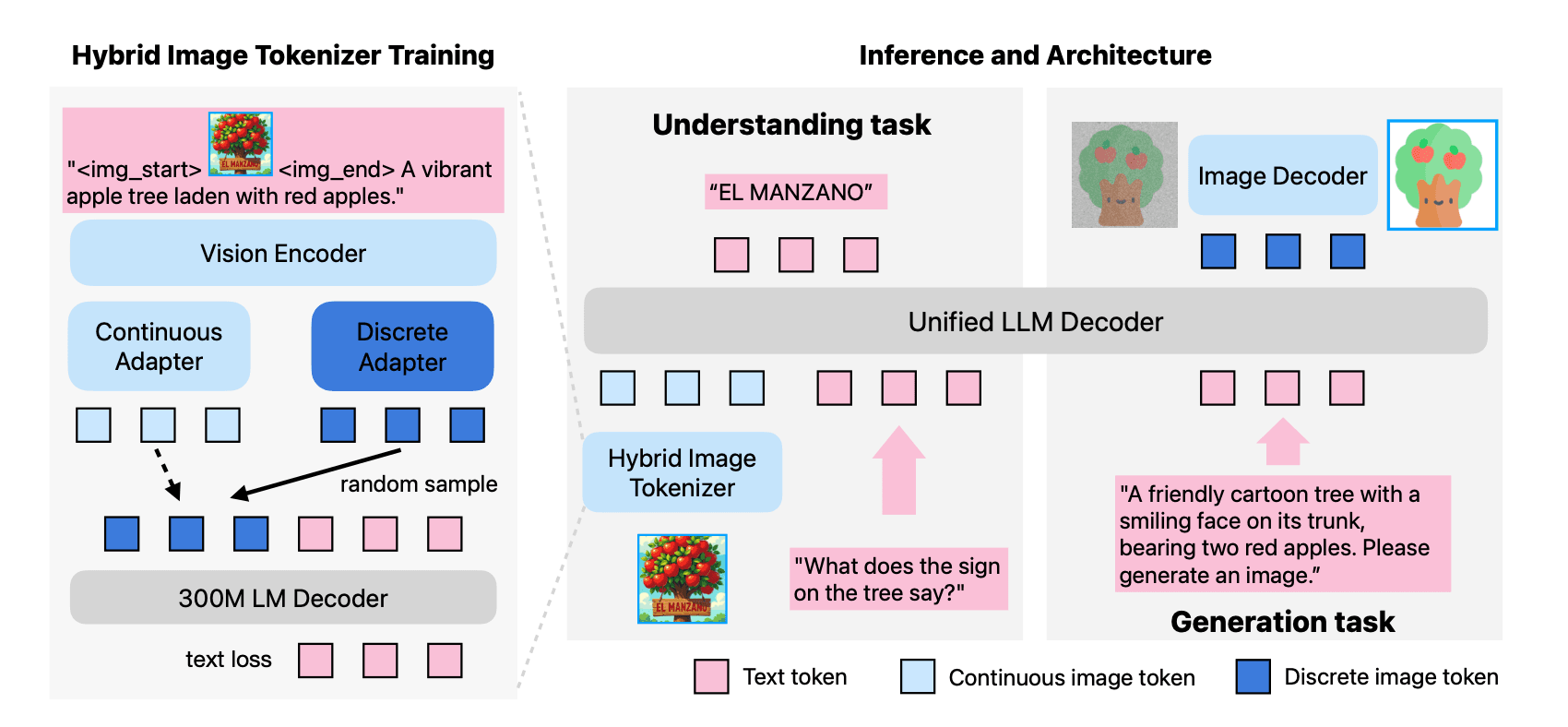
However, existing open-source models often suffer from a performance trade-off between image understanding and generation capabilities. At ICLR, Apple researchers will share MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer. As described in the paper, Manzano is a unified framework designed to reduce this performance trade-off with a simple architectural idea (see Figure 4) and a training recipe that scales well across model sizes.
Manzano uses a single shared vision encoder to feed two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a shared semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, and an auxiliary diffusion decoder then translates the image tokens into pixels. This architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation.
At ICLR, Apple researchers will also share Sharp Monocular View Synthesis in Less Than a Second, which presents a method for producing a 3D Gaussian representation from a photograph, using a single forward pass through a neural network in less than a second on a standard GPU. The resulting representation can then be rendered in real time from nearby views, as a high-resolution photorealistic 3D scene (see Figure 5).
Called SHARP (Single-image High-Accuracy Real-time Parallax), this technique delivers a representation that is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It also sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude.
To enable the community to further explore and build on this approach, code is available here.
ICLR attendees will be able to experience this work firsthand in a demo at the Apple booth #204 during exhibition hours.

Protein folding is a foundational yet notoriously challenging problem in computational biology. At its core, this problem involves predicting the precise three-dimensional coordinates for each atom within a protein structure, based solely on its amino acid sequence (i.e., a string of characters with 20 possible values for each character). Predicting the 3D structure of proteins is critically important because a protein’s function is inherently linked to its spatial configuration. Breakthroughs in this area enable researchers to rapidly design and understand proteins, potentially revolutionizing drug discovery, biotechnology, and beyond.
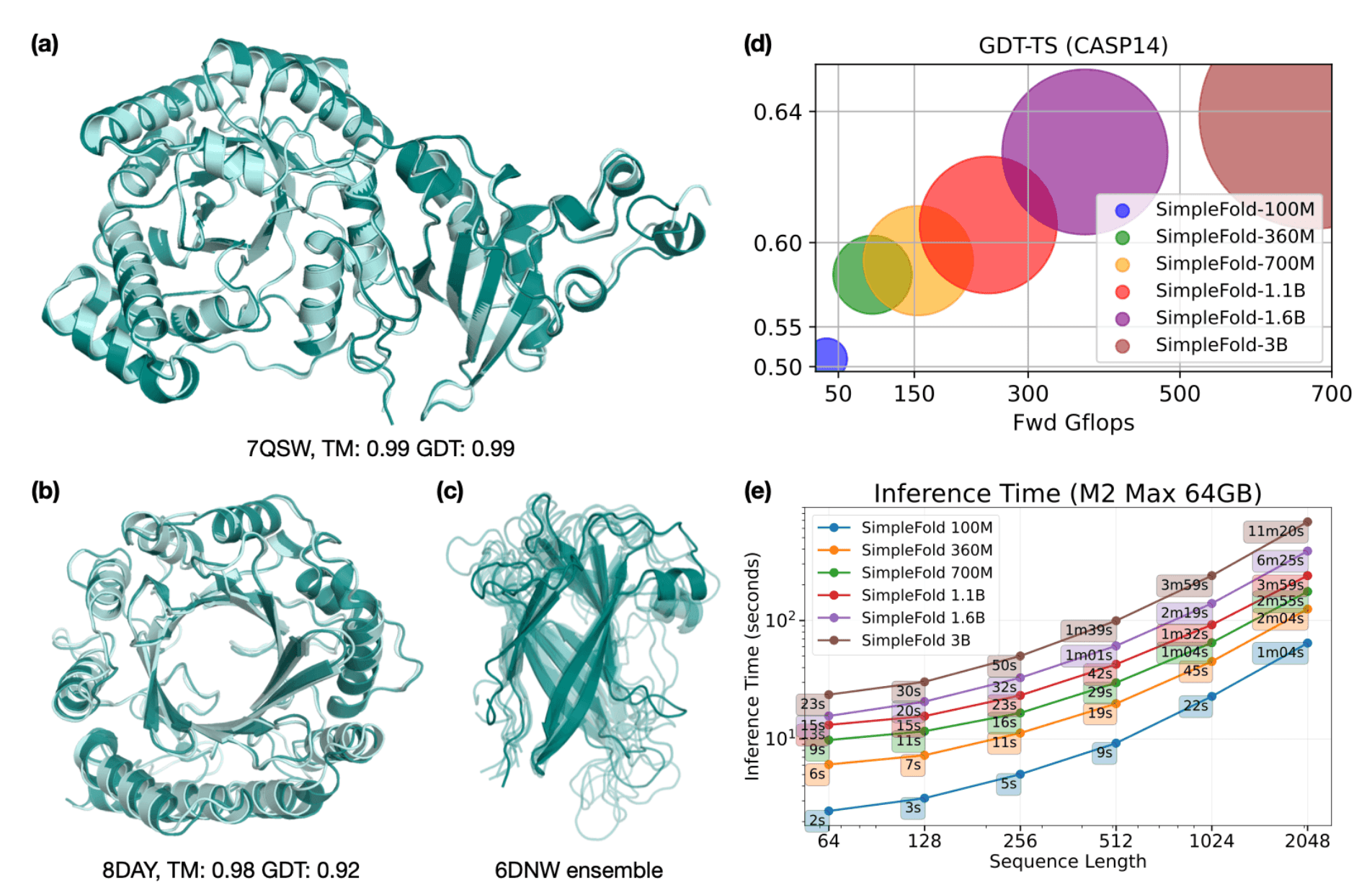
At ICLR, Apple researchers will share SimpleFold: Folding Proteins is Simpler than You Think, which details a new approach that uses a general-purpose architecture based solely on standard transformer blocks (similar to text-to-image or text-to-3D models). This approach allows SimpleFold to dispense with the complex architectural designs of prior approaches, while maintaining performance (see Figure 6). To enable the research community to build on this method, the paper is accompanied by code and model checkpoints that can be efficiently run locally on Mac with Apple silicon using MLX.
During exhibition hours, ICLR attendees will be able to interact with live demos of Apple ML research in booth #204 including:
- SHARP – This demo shows SHARP running on a set of pre-recorded images or images captured directly by the user during the demo. Visitors will experience the fast process from selecting an image, processing it with SHARP, and viewing the generated 3D Gaussian point cloud on iPad Pro with the M5 chip.
- Local LLM inference on Apple silicon with MLX – This demo will showcase on-device LLM inference on a MacBook Pro with M5 Max using MLX, Apple’s open-source array framework purpose-built for Apple silicon, running a quantized frontier coding model entirely locally within Xcode’s native development environment. The full stack — MLX, mlx-lm, and model weights — is open source, inviting the research community to build on and extend these methods independently.
We are proud to again sponsor affinity groups hosting events onsite at ICLR, including Women in Machine Learning (WiML) (social on April 24), and Queer in AI (social on April 25). In addition to supporting these groups with sponsorship, Apple employees will also be participating in these and other affinity events.
ICLR brings together professionals dedicated to the advancement of deep learning, and Apple is proud to again share innovative new research at the event and connect with the community attending it. This post highlights just a selection of the works Apple ML researchers will present at ICLR 2026, and a comprehensive overview and schedule of our participation can be found here.