

The process of adding noise to a signal must be probabilistic (i.e. predictable). The model is shown an audio signal and then instructed to predict the same signal with a small amount of Gaussian noise added to it. Because of its properties, Gaussian noise is most commonly used but it is not required. The noise must be defined by probabilistic distribution, meaning that it follows a specific pattern that is consistently predictable. This process of instructing the model to add small amounts of predictable noise to the audio signal is repeated for a number of steps until the signal has effectively become just noise.

For example, let’s take a one-shot sample of a snare drum. The U-Net is provided this snare sample and it is asked to reconstruct that snare sound, but with a little noise added making it sound a little less clean. Then this slightly noisy snare sample is provided to the model, and it is again instructed to reconstruct this snare sample with even more noise. This cycle is repeated until it sounds as if the snare sample no longer exists, rather only white noise remains. The model is then taught how to do this for a wide range of sounds. Once it becomes an expert at predicting how to add noise to an input audio signal, because the process is probabilistic, it can simply be reversed so that at each step a little noise is removed. This is how the model can generate a snare sample when provided with white noise.
Because of the probabilistic nature of this process, some incredible capabilities arise, specifically the ability to simulate creativity.
Let’s continue with our snare example. Imagine the model was trained on thousands of one-shot snare samples. You would imagine that it could take some white noise and then turn it into any one of these snare samples. However, that is not exactly how the model learns. Because it is shown such a wide range of sounds, it instead learns to create sounds that are generally similar to any of the snares that it has been trained on, but not exactly. This is how brand new sounds are created and these models appear to exhibit a spark of creativity.
To illustrate this, let’s use the following sketch.
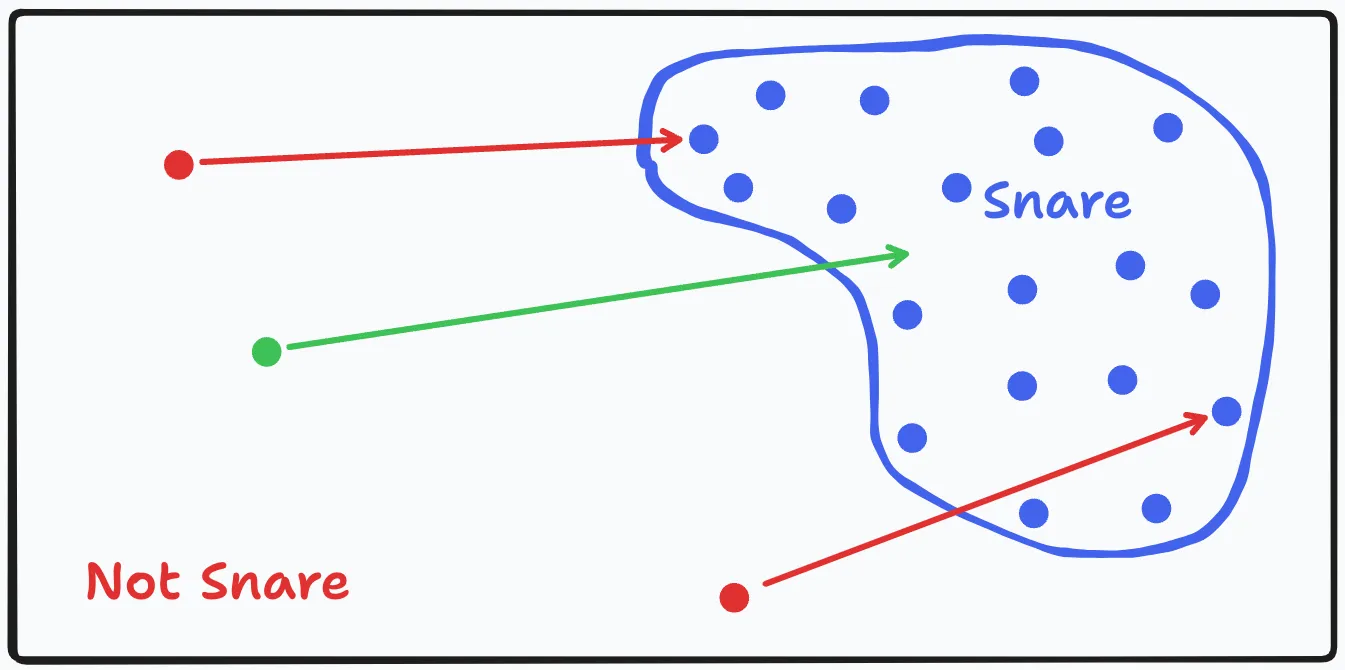
Pretend that all possible sounds, from guitar strums to dog barks to white noise, can be plotted on a 2-dimensional plane represented by the black rectangle in the image above. Within this space, there is a region where snare hits exist. They are somewhat grouped together because of their similar timbral and transient characteristics. This is shown by the blue blob and each blue dot is representative of a single snare sample that we trained our model on. The red dots represent the fully noised versions of the snares the model was trained on and correspond to their un-noised blue dot counterparts.
In essence, our model learned to take dots from the “not snare” region and bring them into the “snare” region. So if we take a new green dot in the “not snare” region (e.g. random noise) that does not correspond to any blue dot, and ask our model to bring it into the “snare” region, it will bring it to a new location within that “snare” region. This is the model generating a “new” snare sample that contains some similarities to all other snares it was trained on in the snare region, but also some new unknown characteristics.
This concept can be applied to any type of sound, including full songs. This is an incredible innovation that can lead to numerous new ways to create. It is important to understand that these models will not create something outside of the bounds of how they are trained, however. As shown in the previous illustration, while our conceptual model can take in any type of sound, it can only produce snare samples similar to those it was trained on. This holds true for any of these audio diffusion models. Because of this, it is critical to train models on extensive datasets so the known regions (like the snare region) are sufficiently diverse and large enough to not simply copy the training data.
All of this means that no model can replicate human creativity, just simulate variations of it.
Applications of Diffusion Models
These models will not magically generate new genres or explore unknown sonic landscapes as humans do. With this understanding, these generative models should not be viewed as a replacement for human creativity, but rather as tools that can enhance creativity. Below are just a few ways that this technology can be leveraged for creative means:
- Creativity Through Curation: Searching through sample packs to find a desired sound is a common practice in production. These models can effectively be used as a version of an “unlimited sample pack”, enhancing an artist’s creativity through the curation of sounds.
- Voice Transfer: Just like how diffusion models can take random noise and change it into recognizable audio, they can also be fed other sounds and “transfer” them to another type of sound. If we take our previous snare model, for example, and feed it a kick drum sample instead of white noise, it will take the kick sample and begin to morph it into a snare sound. This allows for very unique creations, being able to combine the characteristics of multiple different sounds.
- Sound Variability (Humanization): When humans play a live instrument, such as a hi-hat on a drum set, there is always inherent variability in each hit. Various virtual instruments have attempted to simulate this via a number of different methods, but can still sound artificial and lack character. Audio diffusion allows for the unlimited variation of a single sound, which can add a human element to an audio sample. For example, if you program a drum kit, audio diffusion can be leveraged so that each hit is slightly different in timbre, velocity, attack, etc. to humanize what might sound like a stale performance.
- Sound Design Adjustments: Similar to the human variability potential, this concept can also be applied to sound design to create slight changes to a sound. Perhaps you mostly like the sound of a door slam sample, but you wish that it had more body or crunch. A diffusion model can take this sample and slightly change it to maintain most of its characteristics while taking on a few new ones. This can add, remove, or change the spectral content of a sound at a more fundamental level than applying an EQ or filter.
- Melody Generation: Similar to surfing through sample packs, audio diffusion models can generate melodies that can spark ideas to build on.
- Stereo Effect: There are several different mixing tricks to add stereo width to a single-channel (mono) sound. However, they can often add undesired coloration, delay, or phase shifts. Audio diffusion can be leveraged to generate a sound nearly identical to the mono sound, but different enough in its content to expand the stereo width while avoiding many of the unwanted phenomena.
- Super Resolution: Audio diffusion models can enhance the resolution and quality of audio recordings, making them clearer and more detailed. This can be particularly useful in audio restoration or when working with low-quality recordings.
- Inpainting: Diffusion models can be leveraged to fill in missing or corrupted parts of audio signals, restoring them to their original or improved state. This is valuable for repairing damaged audio recordings, completing sections of audio that may be missing, or adding transitions between audio clips.
There is no doubt that these new generative AI models are incredible technological advancements, independent of whether they are viewed in a positive or negative light. There are many more aspects to diffusion models that can optimize their performance regarding speed, diversity, and quality, but we have discussed the base principles that govern the functionality of these models. This knowledge provides a deeper context into what it really means when these models are generating “new sounds”.
On a broader level, it is not only the music, itself, that people care about — it is the human element in the creation of that music. Ask yourself, if you were to hear a recording of a virtuosic lightning-fast guitar solo, would you be impressed? It all depends. If it was artificially generated by a virtual MIDI instrument programmed by a producer, you will likely be unphased and may not even like how it sounds. However, if you know an actual guitarist played the solo on a real guitar, or even saw him or her do it, you will be completely enamored by their expertise and precision. We are drawn to the deftness in a performance, the thoughts and emotions behind lyrics, and the considerations that go into each decision when crafting a song.
While these incredible advancements have led to some existential dread for artists and producers, AI can never take that human element away from the sounds and music that we create. So we should approach these new advancements with the intent that they are tools for enhancing artists’ creativity rather than replacing it.