

Brain-computer interfaces (BCIs) are finally having their ‘foundation model’ moment. Zyphra, a research lab focused on large-scale models, recently released ZUNA, a 380M-parameter foundation model specifically for EEG signals. ZUNA is a masked diffusion auto-encoder designed to perform channel infilling and super-resolution for any electrode layout. This release includes weights under an Apache-2.0 license and an MNE-compatible inference stack.
The Problem with ‘Brittle’ EEG Models
For decades, researchers have struggled with the ‘Wild West’ of EEG data. Different datasets use varying numbers of channels and inconsistent electrode positions. Most deep learning models are trained on fixed channel montages, making them fail when applied to new datasets or recording conditions. Additionally, EEG measurements are often plagued by noise from electrode shifts or subject movement.
ZUNA’s 4D Architecture: Spatial Intelligence
ZUNA solves the generalizability problem by treating brain signals as spatially grounded data. Instead of assuming a fixed grid, ZUNA injects spatiotemporal structure via a 4D rotary positional encoding (4D RoPE).
The model tokenizes multichannel EEG into short temporal windows of 0.125 seconds, or 32 samples. Each token is mapped to a 4D coordinate: its 3D scalp location (x, y, z) and its coarse-time index (t). This allows the model to process arbitrary channel subsets and positions. Because it relies on positional embeddings rather than a fixed schema, ZUNA can ‘imagine’ signal data at any point on the head where a sensor might be missing.
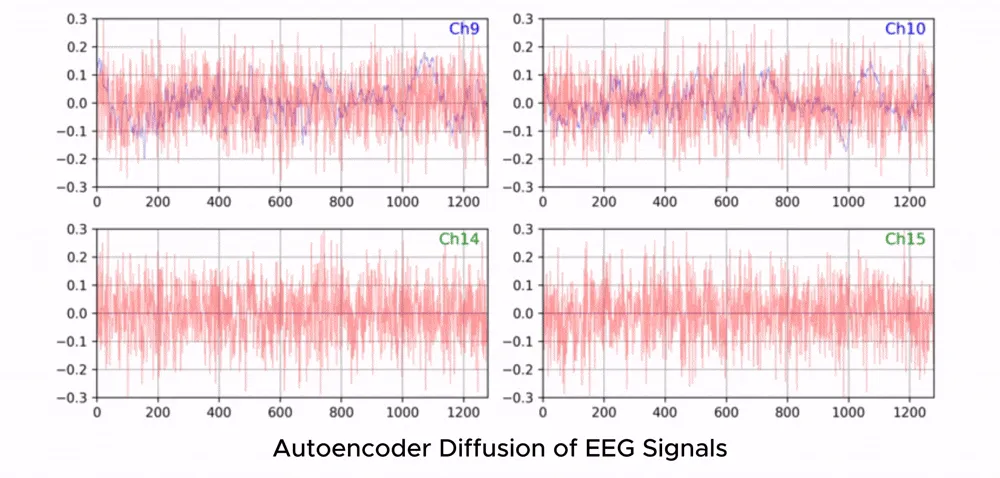
Diffusion as a Generative Engine
ZUNA uses a diffusion approach because EEG signals are continuous and real-valued. The model pairs a diffusion decoder with an encoder that stores signal information in a latent bottleneck.
During training, Zyphra used a heavy channel-dropout objective. They randomly dropped 90% of channels, replacing them with zeros in the encoder input. The model was then tasked with reconstructing these ‘masked’ signals from the information in the remaining 10% of channels. This forced the model to learn deep cross-channel correlations and a powerful internal representation of brain activity.
The Massive Data Pipeline: 2 Million Hours
Data quality is the heartbeat of any foundation model. Zyphra aggregated a harmonized corpus spanning 208 public datasets. This massive collection includes:
- 2 million channel-hours of EEG recordings.
- Over 24 million non-overlapping 5-second samples.
- A wide range of channel counts from 2 to 256 per recording.
The preprocessing pipeline standardized all signals to a common sampling rate of 256 Hz. They used MNE-Python to apply high-pass filters at 0.5 Hz and an adaptive notch filter to remove line noise. Signals were then z-score normalized to ensure zero-mean and unit-variance while preserving spatial structure.
Benchmarks: Killing the Spherical Spline
For years, the industry standard for filling in missing EEG data has been spherical-spline interpolation. While splines are useful for capturing local smoothness, they have no ‘learned prior’ and fail when gaps between sensors grow too large.
ZUNA consistently outperforms spherical-spline interpolation across multiple benchmarks, including the ANPHY-Sleep dataset and the BCI2000 motor-imagery dataset. The performance gap widens significantly at higher dropout rates. In extreme 90% dropout scenarios—essentially 10x upsampling—ZUNA maintains high reconstruction fidelity while spline methods degrade sharply.

Key Takeaways
- Universal Generalization: ZUNA is a 380M-parameter model that works with any EEG system, regardless of the number or position of electrodes. Unlike previous AI models limited to fixed layouts, it generalizes across diverse datasets and novel channel positions.
- 4D Spatiotemporal Intelligence: The model uses a 4D Rotary Positional Encoding (4D RoPE) system to map brain signals across 3D space (x, y, z) and time (t). This allow it to ‘understand’ the physical geometry of the scalp and accurately predict missing data.
- Superior Channel Reconstruction: By training as a masked diffusion autoencoder, ZUNA significantly outperforms traditional spherical-spline interpolation. It excels at ‘super-resolution,’ maintaining high accuracy even when up to 90% of the brain’s signals are missing or corrupted.
- Massive Training Scale: The model was trained on a harmonized corpus of 208 datasets, totaling approximately 2 million channel-hours and 24 million unique 5-second samples. This scale allows it to learn deep cross-channel correlations that simpler geometric methods miss.
Check out the Paper, Technical Details, Repo and Model Weights. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
